My analysis of the Craven County slave testimonies left me with pressing questions about the antebellum slave system. These questions included:
- What kind of pre-Civil War resident owned slaves, and what was their place in society? How large were most antebellum slave holdings?
- In the years before the Civil War, did most slaves live in their owners’ houses or did they have their own dwellings? About how many slaves would have lived in a single slave dwelling?
- What kinds of work were most antebellum slaves engaged in? For those antebellum slaves involved in agriculture, what were the most popular crops?
- Is there evidence of slave breeding in the years before the Civil War (i.e. a high proportion of children and women of childbearing age)?
- What were the connections between antebellum slaveholding families?
These questions marked “gaps” within the dominant narrative of Craven County history and culture. In order to fill these gaps, I looked to historical population data for more information. By far, the most helpful and complete data came from the 1860 Federal Census.
The 1860 Federal Census is an important resource for late-period slave research. It is one of only two censes to enumerate enslaved people. In Craven County, it is also the only antebellum census to break down its enumerations by specific location. For each enslaved person living in Craven the 1860 Federal Census lists their age, sex, and color, as well as their township of residence and their master’s name. It also states whether the person was a fugitive from the state, whether they were manumitted, whether they were disabled, and the number of slave houses they were provided. For each slave owner, it lists their township of residence, name, age, sex, color, birthplace, occupation, value of real estate, and value of personal estate. It also tells us whether they married within the previous year, if they were disabled, a pauper, or a convict, whether they were able to read and speak English, and whether they attended school within the previous year. The 1860 Census also contains information on the farming and manufacturing operations of each Craven County slaveholder, including data on what and how much they produced on a yearly basis.
Unfortunately, each of these sets of information is listed in a different section of the census. These sections are called “schedules.” Each schedule can stretch over dozens of pages, and must be explored individually. For example, if one wants to see how many slaves a particular farmer owned, as well as the crops his farm produced, one would have to check the the Slave Schedule and then the Agricultural Schedule for his name. This makes it very difficult to build a comprehensive picture of each slaveholding household and nearly impossible to identify patterns within the larger community of enslaved people and their owners.
In Beyond the Vale, I explore the utility of combining the information from various census schedules into a single database. The first step in this process was to select a single township on which to focus my research. My criteria for selection dictated that the township have enough enslaved individuals to form an adequate data set, and that its characteristics reflect those of a “typical” Craven County slaveholding community in 1860. With these criteria in mind, I chose Gooding’s Township, a rural farming township located south of the Neuse River and east of Hancock’s Creek. In 1860, the majority of enslaved people in Craven County were held in rural areas like Gooding’s. Some of these areas, such as Reeves’ Township, were quite small in terms of slave holdings. Others, like North of the Neuse River Township, were large. Gooding’s falls somewhere in the lower middle, making its data sizeable yet easy-to-manage. In 1860, it was home to just over 300 enslaved people. One of these individuals was most likely my ancestor, Isariah.
From my initial research into Isariah’s life, I was already familiar with many of Gooding’s slaveholding families. This made it easier to compile the census information into a single database. I began by gathering information from Schedule Two of the 1860 Federal Census, also known as the Slave Schedule (see fig. 1). From this part of the census, I listed the age, sex, and race of each bondsperson. I then included the number of slave dwellings provided by the slaveholder and the total number of enslaved people owned. I included this data because I knew that it would prove helpful in answering questions regarding the size and composition of area slave holdings as well as the living situation of each enslaved person.
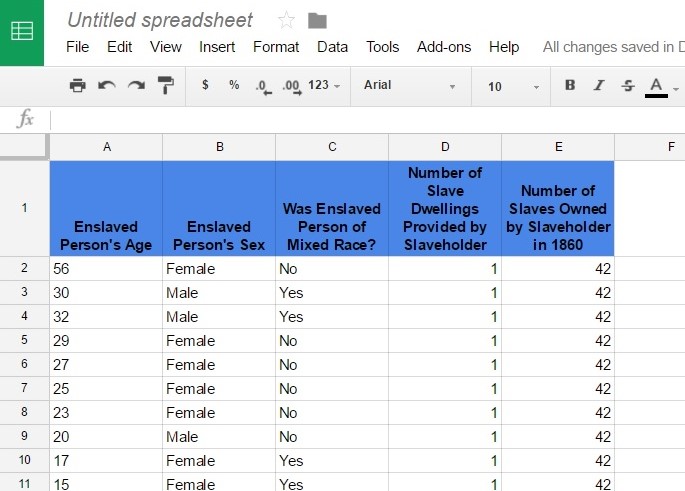
My next step was to add the first and last names of each enslaved person’s owner (see fig. 2). I then gathered the owners’ occupations, sexes, and races from Schedule One, the portion of the census dealing with free individuals. I also included whether the slave owner was a minor, how many free residents lived in their household, and the values of their real and personal property. This information was included in order to help determine what kind of Craven County resident owned slaves and what their place in society was.
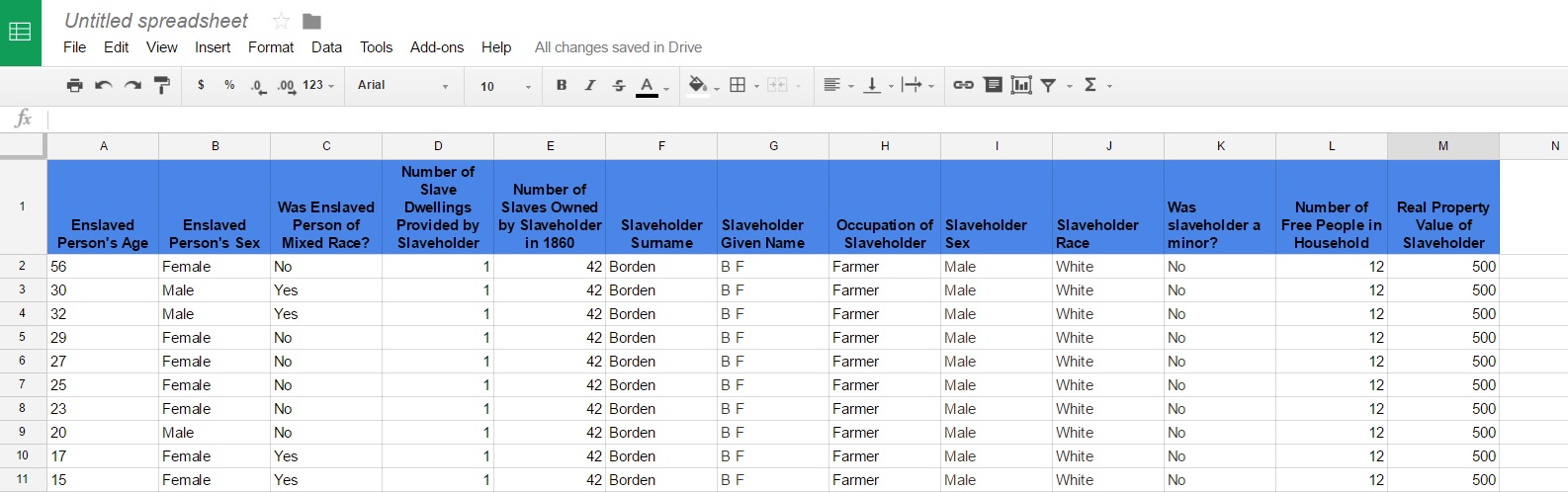
Next, I gathered information from the Agricultural Schedule, or Schedule Four (see fig. 3). To do this, I looked up the name of each slaveholder who was involved in agriculture. I then listed the top crop for each slaveholder and whether or not they were involved in cotton, tobacco, or rice cultivation. This data provides a clear view of the types of work Gooding’s enslaved community was engaged in.
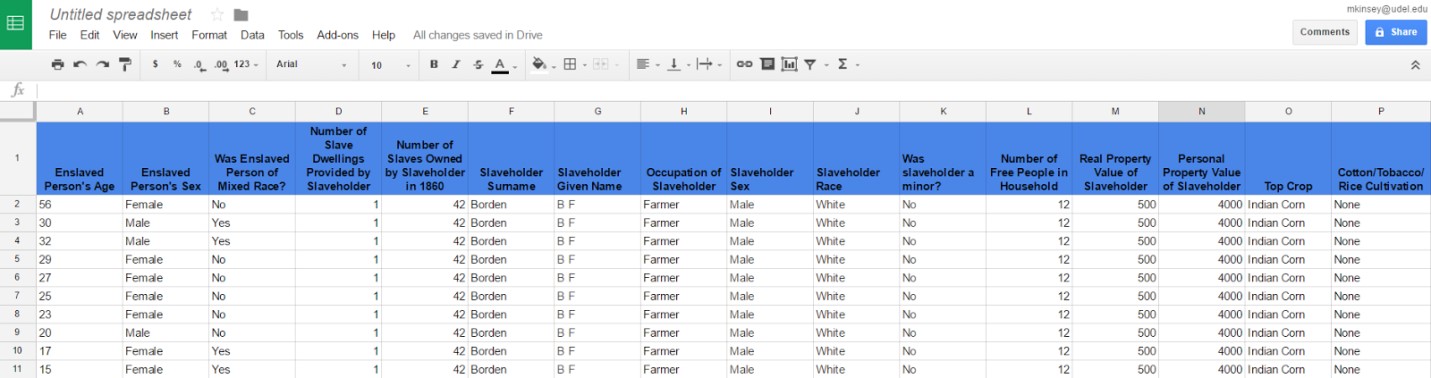
I used the same approach when gathering data from the Manufacturing Schedule (Schedule Five) and included whether or not the slaveholder was involved in the production of timber, turpentine, or tar (see fig. 4). This gave me further information on the types of work the enslaved community performed.
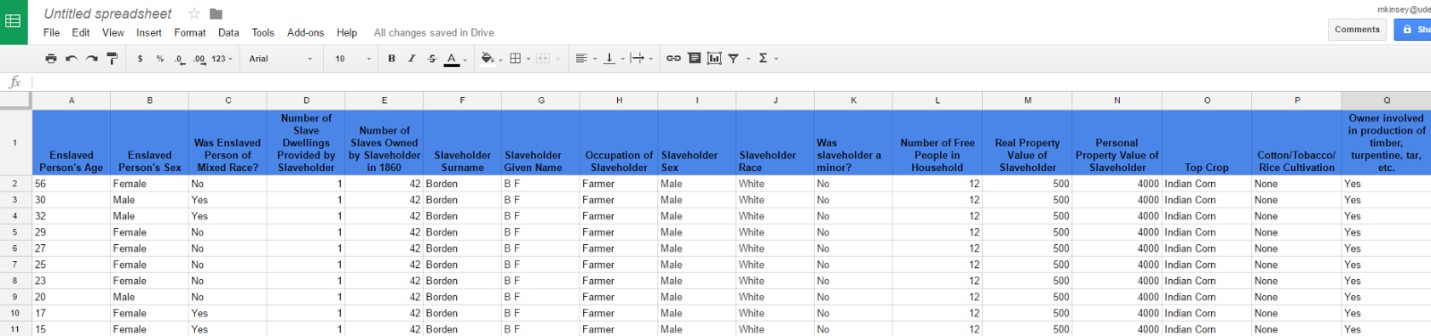
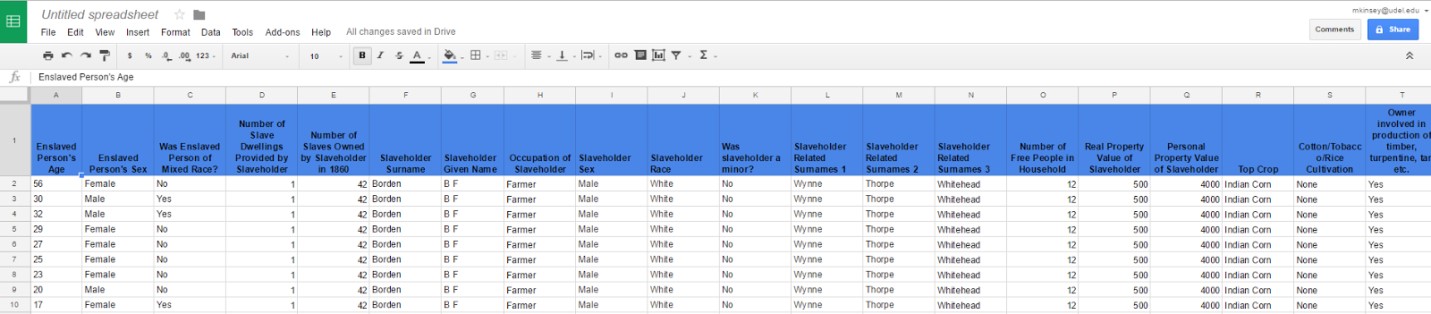
My next step was to obtain information on related surnames for each slaveholder (see fig. 5). I did this by searching for each individual in the county marriage records and by reapproaching the Free Population Schedule. For married women, I noted their maiden name. For married men, I noted the maiden names of their spouses. For any family with people living in their household who did not share their surname, I listed those additional surnames. I did this in the hopes that it would allow me to gain a better idea of how slaveholding families were interconnected.
My final step in building the database was to make it easily searchable by individual and by household (see fig. 6). In order to do this, I assigned each individual – both enslaved and free – a unique ID number. I then assigned each household a unique ID number. While the inclusion of ID numbers did not have an immediate impact on my visualization project, I felt that this addition could help later researchers who might have to work with the information in the database more directly.

Overall, this process took a little over two months to complete. One of the reasons for the extended time frame is that the census is inconsistent. Individuals listed as holding slaves in Gooding’s are not always listed as living in Gooding’s, and vice-versa. This created confusion as to who should be included in the database and who should not. In addition, names sometimes vary from one part of the census to another. These variations are often significant, such as “Baylor” and “Ballinger” and “Lee” and “Lowe.” I resolved the location inconsistencies by including both slaveholders listed as living in Gooding’s and those listed as holding slaves in Gooding’s in an effort to create the most complete data set possible. The name inconsistencies were resolved by carefully reviewing the details listed for each individual. This helped me to ensure that I was correctly identifying the same person in each part of the census. Examining neighboring families also assisted in this effort.
Another challenge concerned the language used in the census. Some of the terms, especially those regarding race and disability, are now considered pejorative and/or inaccurate. I changed this language in my database and reformatted the data accordingly. For example, the original census categorizes enslaved individuals as either “black” or “mulatto.” Instead, I created a yes/no column designed to indicate whether or not the person was of mixed race.
I also wanted to ensure that enslaved people and slave holders were described as similarly as possible. This was difficult considering that the 1860 Federal Census does not list enslaved people by name. I realized that I would have to resort to using ID numbers to differentiate one individual from another. However, I did not want to create a situation in which enslaved people were identified only by numbers, while slaveholders were identified by name. I ultimately decided to assign IDs to both slaves and slaveholders. This in turn led me to create housing IDs for each individual, a unique feature which links together every person, both enslaved and free, dwelling within a given unit. If one compares both the slaveholder IDs and the housing IDs it becomes clear that multiple slaveholders often resided together. I had struggled with how to represent this in the database, and the ID assignments made the process much easier.